【2019年版】Pythonの勉強手順まとめ、初心者に残す道しるべ【独学入門】
どうも、WEBトマトです。WEB制作会社でWEBエンジニアとして働いている私ですが、空いた時間を利用してPythonを学んでみようと思います、スキルアップしていかないとダメだ。
Pythonに興味があるプログラミング初心者向けの記事になります。
この記事では、筆者が「Python」を独学で勉強した手順について紹介しています、内容の効率性は別にして「この人はこういう感じで学んでいるんだ」と参考程度に読んでもらえればなと思います、もちろん真似して追いかけてもOK。
「Python」を始めよう、初心者はここから
「Python」については知識ゼロなのでプログラミング初心者のつもりで臨みたいと思います、まずは基礎的な部分から学んでいきます。
※Windows環境が前提ではありますが、Mac環境でも問題ありません、コマンドプロンプトの部分をターミナルに置き換えるなどして読み進めて頂けるといいかと思います。
①:プロゲートで雰囲気を掴む
まず最初にProgate(プロゲート)を利用して「Python」の雰囲気を掴みたいと思います、といってもスライドを流し読みするだけなので15分もかかりません。笑
プログラミングを勉強におけるプロゲートの利用は正直時間の無駄感は否めません(他言語の経験がある人は特に)、なのでここはスキップしてもいいかなと思います、やるにしても1時間以上かけてはダメですね。
②:Pythonのインストールと確認

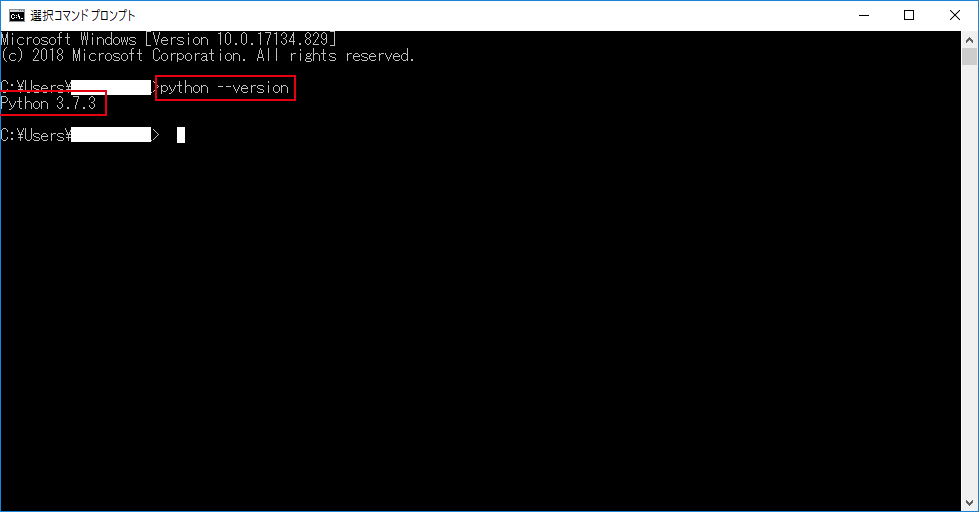
プロゲートでウォーミングアップが済んだらPython環境を構築します、すぐ終わるので構える必要はありません、Python公式サイトにアクセスして「Downloads」からPythonの最新版(私は[3.7.3]でした)を保存して開きます。
インストール画面が立ち上がったら下にあるチェックボックス2つにチェックが入っていることを確認し、「Install Now」をクリック。
完了したらコマンドプロンプトを立ち上げてpython --versionと入力しEnterを押します、上記スクショのようにPythonのバージョンが返ってきたらセットアップ完了です、お疲れさまでした。
③:開発環境を整えてご挨拶「Hellow World」
Pythonをインストールしたら開発環境(IDE)を準備します、IDEに関してはJetBrains産の「PyCharm」、GitHub産の「Atom」、皆大好き「SublimeText」など色々ありますが、正直どれでもいいのかなというところで私は天下のMicrosoftが作る「Visual Studio Code」を採用、業務でも使い慣れているし評判が良いからというそれだけの理由です。
便利な設定:Visual Studio Codeの場合
私と同じく「Visual Studio Code(以下:vscode)」を利用する方向けに便利な設定について紹介しておきます、これから紹介するプラグイン(拡張機能)を追加しておきましょう。
※プラグインは画面左にある四角のアイコン ![]() から追加できます。
から追加できます。
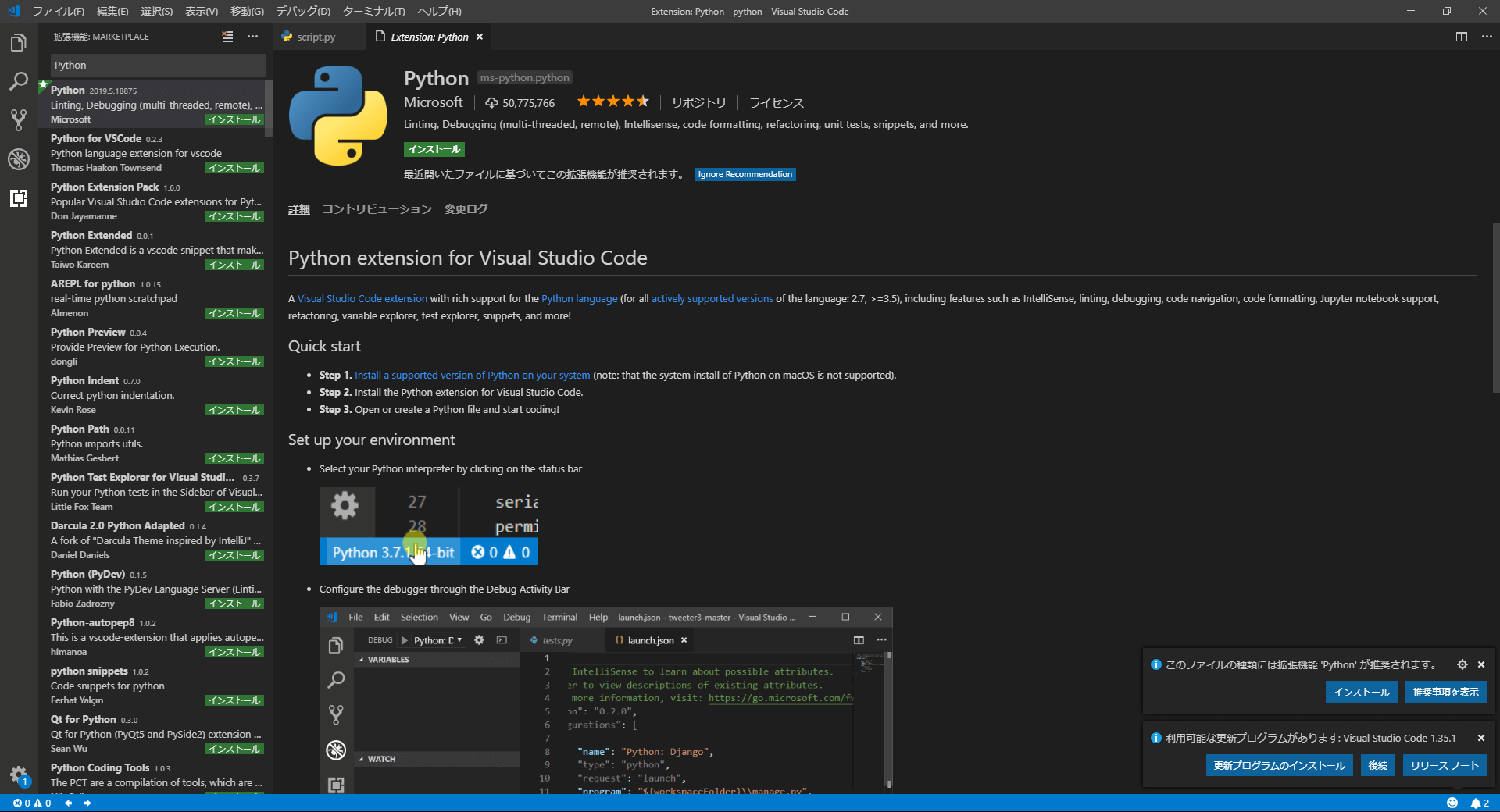
- Japanese Language Pack for VS Code:vscodeを日本語化させる
- Python:vscodeでPythonを使えるようにする拡張機能
上の二つは必須レベルです、必ず入れておきましょう。
とりあえず「Hellow World」
Pythonプロラグミングの第一歩としてお決まりの「Hellow World」を出力してみます、適当にディレクトリを作成して、vscodeで開きます。Python > sample-01とかで大丈夫です。
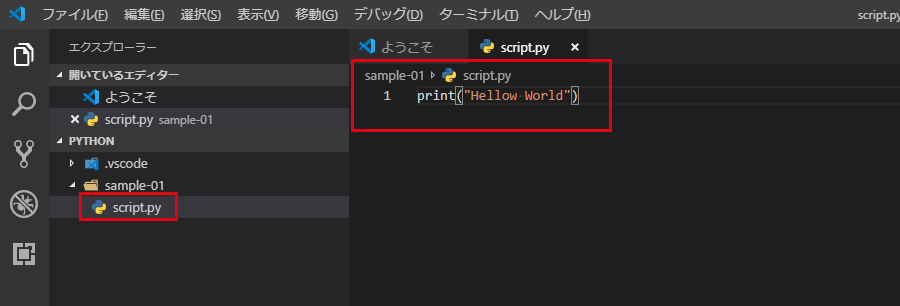
フォルダの中に拡張子.pyでPythonのスクリプトファイルを作成し、print("Hellow World")と記述して保存します。
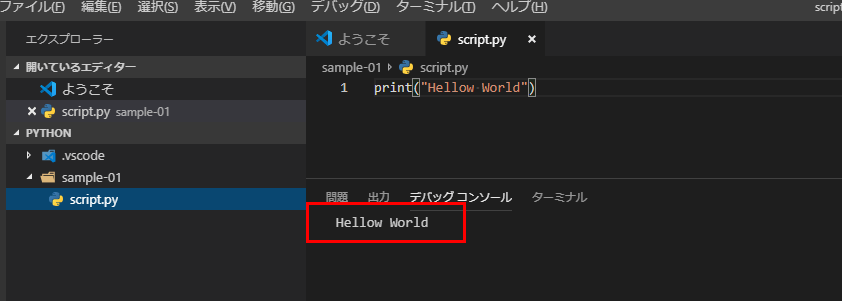
F5を押してPython Fileを実行し、下のコンソールに“Hellow World”と表示されれば成功です、Pythonプラグラミングの世界へようこそ!、、、私が言うのは何か変ですね。笑
※上手くいかない時はコードに間違いがないか、画面の端にエラーが出ていないか確認してください。
「Python」を使って色々動かしてみる【基礎編】
「Python」を学習する環境を整えて実際にコードも動かしたところで勉強開始、正直なところ基本構文(if文とかfo分とか基本的なやつ)はスルーして何か作りながら覚えるのがベストと私は考えます。
なので、Pythonを使って何をしたいか?何を作りたいかを明確にした上で、それを作るために必要なことを逆算し細分化して機能ごとに作って学んでいくのがいいかなと、最終的に全部ガッチャンコして(組合わせて)作品が完成することを目指します。
作品の完成度が高ければポートフォリオとしても使えます(転職・就職するかは別として)、最初は簡単なものでもいいですが、徐々に難易度を上げて実用性のあるものを作るようにしましょう、そっちの方が勉強になる。
作って学ぶ時は現実でも使えるものをイメージして取り組むのがオススメ、自分の中で完結するものは自己満として消化されがちでスキルとして身に付きにくい、こんなものがあったらを意識してみるといい。
WEBサイトからデータを取得「データ収集」
Pythonといえばスクレイピング、データ収集を自動化させるプログラムを作る時はPythonが真っ先に挙げられるほどメジャー、私が作りたいツールにはここらへんの知識が必須なのでPython環境下のスクレイピング処理について学んでみようと思う。
ライブラリを使ったスクレイピング処理について
- 「Requests」「BeatuifulSoup」ライブラリを使用
- 取得先ページのURLをセット
- URLを元にデータを取得
- 取得したデータを解析
「PythonにおけるWEBスクレイピング入門」という記事がかなり参考になりました、確かに簡単に実装できた、「PythonでWebページを取得できたかどうかのエラーチェックと安全な中止の仕方」という記事も併せて読むとよさそう。
WEBアプリケーションを構築してみる
Pythonでできることの一つが「WEBアプリ開発」、これを簡単に体験すべく「Flask」というフレームワークを使ってWEBアプリケーションを構築してみました、例のごとく「Hellow World」から見てみましょう。
「Flask」を使ったWEBアプリケーション構築について
- 「Flask」をインストールし読み込む
- ファイル・ディレクトリをセットする
ネットに落ちているコードだけで「Hellow World」まで簡単に出力できます、小規模なWEBアプリに最適というのはまさにその通りでかなり手軽に使える、詳細についてはまた別記事で。
「Python」専用ライブラリ一覧

ネットに落ちているコードや参考書を使って勉強していると必ずライブラリ(モジュール)を使用する機会があると思います、その中でも特に重要なものをまとめておきたいと思います。
※筆者自身が独学中の身なので紹介していないライブラリは適時学習してください。
- Requests
- BeatuifulSoup
- lxml
- Selenium
①:Requests
HTTP通信を行いWEBサイトの情報を収集する時に使用するサードパーティー製のライブラリ、シンプルな記述で実装できるので初心者でも簡単に扱えるのが特徴。
pip install requestsと入力②:BeatuifulSoup
HTMLやXMLファイルのデータを解析するための専用ライブラリ、WEBでのデータ収集(スクレイピング)を効率化させるために使用する、データ抽出時はHTMLとCSSの基礎部分の知識は必須、他のライブラリ(requests等)と一緒に使用することがほとんど。
pip install beautifulsoup4と入力サンプルコード「Requests × BeatuifulSoup」
import requests
from bs4 import BeautifulSoup
# 取得したいURL 例:https://sample.com
url = "ここにリンク"
# urlを引数に指定して、HTTPリクエストを送信してHTMLを取得
response = requests.get(url)
# 文字コードを自動でエンコーディング
response.encoding = response.apparent_encoding
# HTML解析
bs = BeautifulSoup(response.text, 'html.parser')
title_tag = bs.find('title')
# コンソールで確認
print(title_tag.text)上のコードは、指定したURL先のデータを取得しタイトルを出力します。
③:lxml
先ほど紹介した「BeatuifulSoup」と同じくHTMLデータ等を解析するプラグイン、使用用途はもちろんスクレイピング、BeatuifulSoupより高速で動くメリットがある。
pip install lxmlと入力サンプルコード「lxml × Requests + (CssSelect)」
import lxml.html
import requests
# 取得したいURL 例:https://sample.com
url = 'ここにリンク'
# urlを引数に指定して、HTTPリクエストを送信してHTMLを取得
target_html = requests.get(url).content
# HTML解析
dom = lxml.html.fromstring(target_html)
# セレクタで抽出
title = dom.cssselect('title')[0].text
# コンソールで確認
print(title)上のコードは、指定したURL先のデータを取得しタイトルを出力します、「Requests × BeatuifulSoup」と比べて記述が若干違うだけでやっていることは同じ。
④:Selenium
仮想ブラウザを立ち上げブラウザ操作を自動化させる際によく使うライブラリ、「Selenium」を使えばログイン情報やブラウザ操作が必要なサイトのスクレイピングも可能になる、色々な用途で使われる万能プラグインです。
pip install seleniumと入力サンプルコード「Selenium × Chromedriver」
from selenium import webdriver
# ドライバの読み込み
driver = webdriver.Chrome(ここにドライバのパス)
# Chromeで指定したページを開く 例:https://sample.com/about/
driver.get("ここにリンク")
# Chromeを閉じる
driver.quit()上のコードはSeleniumを使ってChromedriver経由でChromeブラウザを開いて指定URLにアクセスし、その後ブラウザが自動的に閉じるようになっています、閉じる前に特定の要素をクリックさせることも可能で、ログインが必要なページにもアクセスする事も可能。
これまで紹介したライブラリと比べて実装までの準備が面倒くさいので注意、Windows環境は特に。
終わりに
とりあえず今回はここまで、続きに関しては随時更新していきます、Python学習と並行してブログにまとめていきますのでしばしお待ちください。
分からない事は極力ググってるなどして各自対応してもらえればなと思います、問題にぶち当たった時に自分で解決するのもまた勉強です、巷では「ググる力を身に付ける」なんて言われてますしね。
Pythonに限らず現場ではネットに落ちている情報を拾っては最適化し実装に役立てることも多々あるので、ここらへんの対応力は重要かと思います。
ちなみに、私はPython以外にもiOSアプリ開発の主言語であるSwiftも勉強中ですので、更新頻度はあまり期待しないでください、ブックマークするなどして気長にお待ち頂けると幸いです。
他の人が読んでいる記事
飲食→派遣→IT系ベンチャーに転職。
本業をベーシックインカムとし、やりたい事に挑戦するWebエンジニア。